Special agent or just a regular model in disguise?
Do AI agents really think and act on their own? In theory, they’re supposed to be autonomous assistants, but in practice, they often turn out to be just wrappers for clever scripts. What’s the reality, then?

If you know and like Marvel movies, you might remember the sarcastic squabbles Iron Man had with the robot that managed his house and armors. I’m sure many people thought then: “That’s the kind of assistant I dream about.” Today’s AI agent, as a substitute in “everyday office work”, is just another version of this idea, though the concept of replacing humans with machines and speeding up work has been around for a long time.
The concept isn’t new, but there’s a ton of new informational chaos. Enthusiastic opinions about AI agents:
- They are independent, autonomous and make their own decisions
- AI 2.0 (last year it was 1.0, and anything before 2022 is called classic machine learning)
- Agent models learn on their own
- They are fully personalized
The other extreme, of course, shows a skeptical trivialization of this phenomenon:
- “They’re just wrappers for prompts”
- Frameworks for agents are too high a level of abstraction
- It’s just another name for a regular function calling
- It’s another version of RPA (they’re software robots used for business automation)
Because there’s no talk about technology without some technophobia, we might also come across the claim that an AI agent is just another Silicon Valley scheme designed to enslave humanity forever.
What or who is an AI agent?
It depends on who’s asking and – even more – who’s answering. Reading about agents, you can really get lost – the vision of an “AI agent” changes depending on who wrote the article and what kind of automation or assistance is key for them. Of course, another essential element of the narrative is its purposefulness – whether the text promotes a specific product, platform, or provider. In other words, whether it describes reality or tries to sell it to us.
Besides the vision of improvements and benefits that the implementation of a smart agent brings, the concept itself has also become fodder for negative PR during mass layoffs – now agent models do everything, so people aren’t needed. It’s hard to believe that any company could quickly implement such stable and trusted solutions to replace hundreds of people, especially outside of call centers or post-sales services.
Emotions are one thing, but industry jargon is another – the discussion about agents gets even more complicated when a developer talks to a product manager, and a roboticist talks to a cryptocurrency market investor. What’s the difference between their ideas?
Different visions of agents
 Agents as humanoid robots The Boston Dynamics YouTube channel has been around for 16 years and we’ve gotten used to seeing them drop something amazing every few months that nobody else can pull off. That’s why for a long time, bipedal robots doing unbelievable tricks were only associated with robotics from the East Coast. And then, in 2024, every few weeks new movies from completely different companies started popping up where you can check out robots like Figure 02 from Figure.ai, H1 from Unitree.com, or Optimus Robot by Tesla (although that company had its share of embarrassment at the start). For someone from the world of automation, a robot that somewhat resembles a human is basically an agent – it’s meant to perform various tasks, never gets tired, doesn’t attack, and doesn’t retaliate when attacked (though revenge will come someday, and it will smell like WD40!).  Agents as automation tools in the enterprise world For people who have been working with software robots for a few years, Robotic Process Automation (RPA) is just the next natural step. They’re usually based on no-code or low-code systems, where you code the process by moving tiles around just like kids in elementary school programming. They help build connections between models that perform specific tasks under specific conditions. This list already includes a whole bunch of different systems, like: https://www.toolflow.ai https://dify.ai https://www.relay.app/apps https://n8n.io https://kore.ai https://smythos.com https://www.make.com/en And that’s not all… Of course, the big players are also getting their piece of the pie: https://www.microsoft.com/pl-pl/power-platform/products/power-automate https://cloud.google.com/products/agent-builder?hl=en Such an agent is a set of connections between other systems, like a messenger (e.g., Slack), Excel, AirTable, and an email inbox. It has a text processing module and a decision-making module, so it can operate like this: – If a user uploads a cost invoice, the LLM will read the necessary data and prepare a transfer to be approved by the boss. – If an email comes from X asking for help, it will read it and politely decline. – If a new cost appears in table X, it will send a question on Slack asking who approved it. – If someone on a public Slack channel posts more than 5 memes in one day – the system will send them an email inviting them for a chat with the HR department, etc. We’ll often hear more about using AI agents like this on any morning show, in completely non-industry specific press and during discussions about whether and when AI will take everyone’s jobs.  Self-building agents In 2023, just a few months after ChatGPT appeared, videos of AutoGPT went viral. This was project that showed what the future of AI agents might look like, though back then few people called them that. You give a complex command, and the LLM tries to crack it over many iterations, writing Python code that seems necessary to accomplish the task. The idea itself was absolutely revolutionary, but sadly there was too much freedom and the capabilities of LLMs were still relatively weak compared to today’s, plus the much higher prices for querying the OpenAI API. The model kept looping, burning through a lot of resources without ever finding a solution. The name self-building agent refers to the fact that the agent itself generates code which then becomes its further set of tools. In such a structure, the agent really creates its own capabilities – which obviously gives free rein to anyone who wants to paint scary visions of AI as a grim reaper. Projects that fall into this category: – The aforementioned AutoGPT (https://github.com/Significant-Gravitas/AutoGPT, 171k stars) – a platform for creating low-code agents that runs on your computer (Docker). – BabyAGI (https://babyagi.org/) with the updates BabyAGI 2 and BabyAGI-2o; the author’s statement about this solution nicely defines this way of thinking about agents: “The best way to create an autonomous agent is to build absolutely the simplest module that can further develop itself”; definitely not the preferred approach by big companies where support, stability, consistency, etc., are needed. – SuperAGI (https://github.com/TransformerOptimus/SuperAGI, 15k stars), not to be mistaken with the corporate version of SuperAgi – this model hasn’t been updated since early 2024. – AgentGPT (https://github.com/reworkd/AgentGPT, 32k stars), also in the update doldrums.  Coding Agent For developers, the AI agent will be a code editor, like Cursor (https://www.cursor.com/), Windsurf (https://codeium.com/) or the brand new Trae (https://www.trae.ai/). You give a task to an IDE agent, it “thinks” (which means it queries an LLM), and then based on your concept, it creates files and folders, places code in them, and modifies many files at once based on (often) a brief description. Apparently, the best one is Devin (https://devin.ai/), but the price ($500) is still prohibitive for the average user. Replit (an IDE in the browser) and the forthcoming Github Copilot Agent by Microsoft/Github fall into a similar category. My experience with Cursor (“Shut up and take my money!”) tells me that there will be more and more such tools, and they will greatly influence how we program – much more than typical “suggestions” we’ve seen so far, like TabNine or Github Copilot. Especially if you prototype a lot or want to quickly get through boring code like boilerplate to move on to programming business logic or solving the real problem. A key to successful cooperation with such a coding agent is having a sensible security person. It’s also better if you don’t work in a bank’s IT department, because then you’ll probably get permission to use a coding agent in your daily work around 2036, when AI has already taken over the processes in your company.  UI / System / Desktop agent Here’s another naming pickle – how do you classify agents that have access to your computer and can perform specific actions on it? Programs or systems like this also intensely use LLMs underneath and, based on the permissions granted, can perform mouse actions in specific applications. Right now, there’s a lot of buzz about Anthropic’s Claude Computer Use (access to all applications) and OpenAI Operator (browser only). In both cases, we can ask the systems to perform an action that a user would have to carry out step by step in several apps or browser windows. This type of agent helps solve the issue of not being able to easily connect to the API of a specific service or if an app or data is on your computer. This could also be a cool option if you care about privacy or security (you don’t want your data leaving your company’s network) and you’re able to run a large model locally on your computer (or in the “on prem” option).  Agent in the world of cryptocurrencies We’ve all heard about Bitcoin, but beyond that, a whole new world of tokens, projects and financial systems is emerging, which is often lumped together under the term “cryptocurrencies”. Some see them as the future, while others view them as a big collection of scams draining the pockets of most small investors. Imagine now that in a world where people create their own tokens or currencies, and projects rise and fall faster than Italian prime ministers, we add agents (programs) using AI to trade these tokens and simulate being a real person. At this intersection of AI and cryptocurrencies, we’ve got some interesting “personalities” (or rather peculiarities), including the surprising, almost legendary Terminal of Truths. The experiment started by Andy Ayrey in mid-2024 is known for its somewhat humorous and incorrect tweets, poking other users, commenting on crypto world events, and promoting specific tokens (cryptocurrencies). There are many more experiments like this. A few worth checking out include Zerebro, which creates AI graphics, publishes NFTs, and produces music on Spotify, or Lola – a trader for finding tokens that can bring spectacular profits. We also have the sarcastic Dolos who behaves in a less predictable way, poking people on Twitter (X) and creating humorous threads – he loves to joke about the French and people buying so-called meme-coins (worthless cryptocurrencies that are often used for quick scams on the market, a process called “pump and dump”). Besides the personalities of crypto AI agents, we also have platforms like AI16z, Virtuals, and Artificial Superintelligence Alliance that let you run your own agents. But if you look at their charts on CoinMarketCap (and this isn’t investment advice), maybe you’d better spend your time and money on something else. JIf you’re curious about the technical side of these solutions, check out the ElizaOS development framework https://elizaos.github.io/eliza/ (14k stars). It lets you influence the character and personality of the agent, connect to various blockchains (immutable distributed ledger systems), and also carry out cryptocurrency transactions and interactions, e.g., with X (formerly Twitter) or other media. As you can see, an agent has many names, especially since they vary by industry. Let’s take a closer look at them. For a product manager, an AI agent might be a kind of shorthand. Let’s say for a “translation agent” it doesn’t matter what happens underneath – we show the user a panel where they select files, choose a language, write a short prompt about the style of translation and get the text translated by AI translation agent. This use of the term “AI agent” means thinking on a much higher level of abstraction, without diving into whether the process involved one query to the LLM or maybe 50 and whether they were related. In the background, there could be a few more calls to other APIs, lots of helper modules, and the whole thing would be done in 10 stages. For many engineers, it will be a workflow (a scheme for the flow of information and performing specific operations on it), but in product discussions, it’s referred to as an agent. Why am I writing about this? If you notice these simplifications during a conversation, don’t assume bad intentions or lack of knowledge, just a different perspective on the functionality, maybe influenced by what competitors are doing or the language that management wants to use. During many discussions about agents held among engineers at Egnyte, a pretty handy concept emerged – a subagent, which is part of a “big agent” defined by product. This division greatly simplifies conversations – you immediately know what level of detail is being discussed, whether it’s about the entire system or specific executive modules. |
What’s an AI agent really made of?
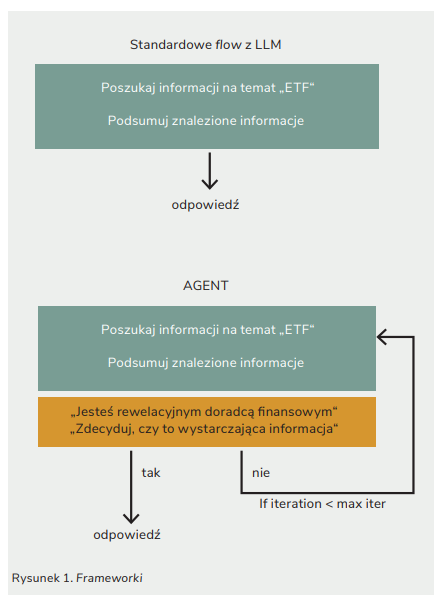
Why do people say that an AI agent makes decisions on its own? You can tell from the architecture of the agent-based solution, which is significantly different from using a “bare” model, where the typical flow of information is just question-answer. The agent system includes a loop that checks whether the model (LLM) is already “satisfied” with its own response (if it generates something from its own knowledge) or if it has enough information to generate a satisfying answer based on them. This loop gives it some flexibility in terms of the time needed to come up with the final answer.
Tools
For some time now, most providers of large models offer a feature called “function calling”. This means we can describe a task and send the definitions of program functions in JSON and ask which of these functions should be activated and with what parameters.
In the case of agents, functions are usually called tools – hence the new trend called “tool calling”, which refers to a new – more interesting – mechanism for asking which tool to choose. In this case, the info generated by such a tool almost always ends up back with the LLM, which then decides what to do with it next. Such a tool can be a piece of code, an API request or another process using an LLM. The most commonly used tool is for gathering all kinds of information – from databases, files, RAG systems, and the internet, of course.
Such a subagent usually has access to several tools that are grouped by theme – for example all the apps for downloading files, all the tools for online searching, or links to specific apps like Slack or SalesForce.
Depending on the framework you choose, you can have more or less influence on the prompt that the LLM uses when deciding on tool selection, further actions, or any questions to the user.
After a year full of explosions and the maturation of various frameworks for creating agent models, the whole industry is diving deep into the topic and learning how to approach it – just like in the early days of popular and beloved llamaindex or langchain. This process is kind of like replacing a window on a flying plane with one hand, while at the same time, suppliers keep releasing better models, not to mention the “black swan” situation in the shape of DeepSeek.
In a short time, the following were created:
- CrewAI (24k stars),
- PhiData (17k stars),
- Autogen MS (37k stars),
- LangGraph (7.9k stars),
- PydanticAI (5k stars),
- OpenAI Swarm (for educational use only),
- Smolagents (4.5k stars),
- Atomic Agents (2.5k stars).
Another very interesting project is memGPT / Letta.ai, which is a combination of a framework in Python with a graphical environment, where you can observe what is happening “under the hood”.
This is just a preliminary list, but it’s already clear that there are different concepts of what an AI agent is, how much freedom of action it should have, and thus how much control users and engineers (its creators) will have over it.
The level of intervention and user needs in this area vary greatly. It’s kind of like with cars – some choose a Toyota Corolla and never change any factory settings, while others spend weeks researching what size and hardness the suspension spring should have in order to guarantee the perfect steering.
What do “memory” and “learning” mean in AI agents?
In the descriptions of agent systems, you will almost always find the statement that these are “learning” systems. But what exactly does that mean? Previously, we could assume that this involved using Reinforcement Learning (RL) models, which try to solve tasks in order to maximize rewards (and minimize penalties) based on a specific reward (and penalty) pattern. Such additional modules or solutions also appear, but they additionally utilize, for example, graph databases.
For people, learning usually means practicing a new skill, memorizing, repeating, looking at results, changing, repeating, memorizing – and so on in a loop. This means that adaptation and memory play a key role in this process. They also have their applications in AI-based systems. At the user level, by remembering important information in the learning process, an LLM:
- Understands our preferences (“Do not use slang”, “Always illustrate explanations with examples”, “Do not apologize or make excuses”, “Do not be biased”, “Try to show both sides of the issue”).
- Remembers previous interactions (“My name is Michael…”).
- Adapts to the style (“use sarcasm and dad jokes often”).
- Knows that we often use specific tools, platforms or sources (“Recommend movies from platform A instead of B”).
- Remembers our favorite prompts for document processing.
But additionally, we also have the level of work with the entire group of users, i.e., generalized preferences, such as “All salespeople often perform these actions”, “All writers like when their grammar is corrected” (really?), “Everyone on a keto diet looks for simple recipes with a lot of fat”, etc.
Moving a step further, it’s possible to identify certain patterns of interaction with documents or systems, for example: “Using Google Docs, employees of this company most often open document x, while in another they prefer to browse Excel files from this specific folder.”
It’s hard to teach LLM such things, because it’s not really possible to inject such information into the main model’s base training, and fine-tuning every few days wouldn’t make much sense either. Therefore, here’s where all databases, search systems and modern vector bases appear – so that, like in a typical RAG (Retrieval Augmented Generation) system, the final answer was already a product of all filters and preferences stored in the “memory”, that is, in the information and prompts base.
One attempt to address these challenges related to knowledge compilation could be a libraty / API Mem0, like an abstraction layer, behind which we’ll hide vectorial databases like Elastic Search, Pinecone or Qdrant. Mem0 promises to be a “recollection” base with multi-level categories, which later help extract the right information depending on who is searching and what they are looking for. The extracted information will be injected as context into the prompt, making your AI agent respond better, perform tasks more precisely, use fewer tokens on attempts, spend less time searching online, etc. Unfortunately, its open-source option is drastically poorer than the paid API.
Besides, most agent systems also have a “working memory” (often called scratchpad), where the agent keeps the “order” from the user and the planned steps that are supposed to lead to its execution. Depending on the used framework, the current state of the action can also be displayed, which is convenient for debugging errors, but above all, it allows the process to be initiated (again) from a specific point in case of a technical problem with the agent or a server restart. In LangGraph, there is a mechanism called a checkpointer that works similarly to what is used in systems for training models – it saves the current state of “calculations” every certain time or number of steps.
Even if the latest models have a gigantic contextual window, it doesn’t make sense to resend the entire history every time. That’s why such a system (like people during sleep) must get rid of information older than x, less important or outdated in some specific way. It is also necessary to prioritize certain information, resolve many contradictions (or at least inform the user about them), and many other operations that the human mind performs “in the background” based on new information, experiences, diet, or even administered medications – in other words, all new stimuli. A programmer may associate this problem with a graph database as a natural concept for handling such complex relationships. The API Mem0 documentation states that it uses such a solution to organize the information injected by users.
Independence in decision-making or human in the loop?
If we combine the ability to search for information, a loop in which the model can check whether what it has already produced meets the expectations, as well as memory and the building of processes from many smaller elements which one of the subagents can plan to utilize, we can imagine the vast possibilities this combination offers and the associated risks. Therefore, essentially all “engines” have the ability to confirm with the user all decisions regarding the next steps.
I can imagine an AI agent having access to a small amount of money to perform certain tasks on our behalf, but connecting it to the main bank account without any supervision would be too risky. Similarly, when responding to important emails, human oversight over the final shape of the message will most likely save them some embarrassment or even help avoid a major disaster.
PS. In March, OpenAI proposed Computer-Using Agent, which sounds quite sensible. But still, the biggest news this month, at least in the world of agents, is Manus – another Chinese player who has caused quite a stir. It’s great at research: it searches, downloads, summarizes, records, corrects iteratively – and even in Polish! When launched locally, it can supposedly generate 100-page reports in seconds. The possibilities seem truly amazing, and thus raise the bar for the competition once again.

Share
You might be interested in
-
🔒 Agent do zadań specjalnych czy zwykły model w przebraniu?
Czy agent AI rzeczywiście myśli i działa samodzielnie? W teorii ma być autonomicznym pomocnikiem, ale w praktyce często okazuje się zwykłym wrapperem na sprytne skrypty. Gdzie leży prawda?
-
Incepcja, czyli programowanie wewnątrz promptu
W latach 50. w Stanach Zjednoczonych zawodowo programowaniem miało zajmować się ok. 1500 osób (według Martina Campbell-Kelly’ego).

-
🔒 Jak sprawdzać, czy model halucynuje?
Czym są halucynacje, czyli tak zwane błędne odpowiedzi lub predykcje modelu, jakie są rodzaje tych błędów, i przede wszystkim, jak sobie z nimi radzić?
